简介
- Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。
- Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
有界与无界数据流
- 无界流: 有定义流开始, 未定义流的结束; 持续产生数据, 需要以特定顺序摄取事件 (如事件的发生顺序), 以便能够推断结果的完整性.
- 有界流: 既定义流的开始, 又定义流的结束; 可以在摄取所有的数据后进行排序计算, 并需要有序摄取, 有界流处理通常被称为批处理.
特点
- 事件驱动型
- 流批一体
- 分层api
- SQL/Table API (dynamic tables)
- DataStream API (streams, windows)
- ProcessFunction (events, state, time)
应用场景
- 电商和市场营销
- 物联网 (IOT)
- 传感器实时数据采集和显示, 实时报警, 交通运输业
- 电信业
- 银行和金融业
Flink vs Spark Streaming
- Spark Streaming 是微批 (micro-batching) 处理, 运行时需要指定批处理时间, 每次job处理一个批次的DStream (一组一组的小批数据RDD的集合)
- Flink 是标准的流执行模式, 基本数据模型是DataStream 以及事件 (Event) 序列, 一个事件处理完成后可以直接发往下一个节点进行处理
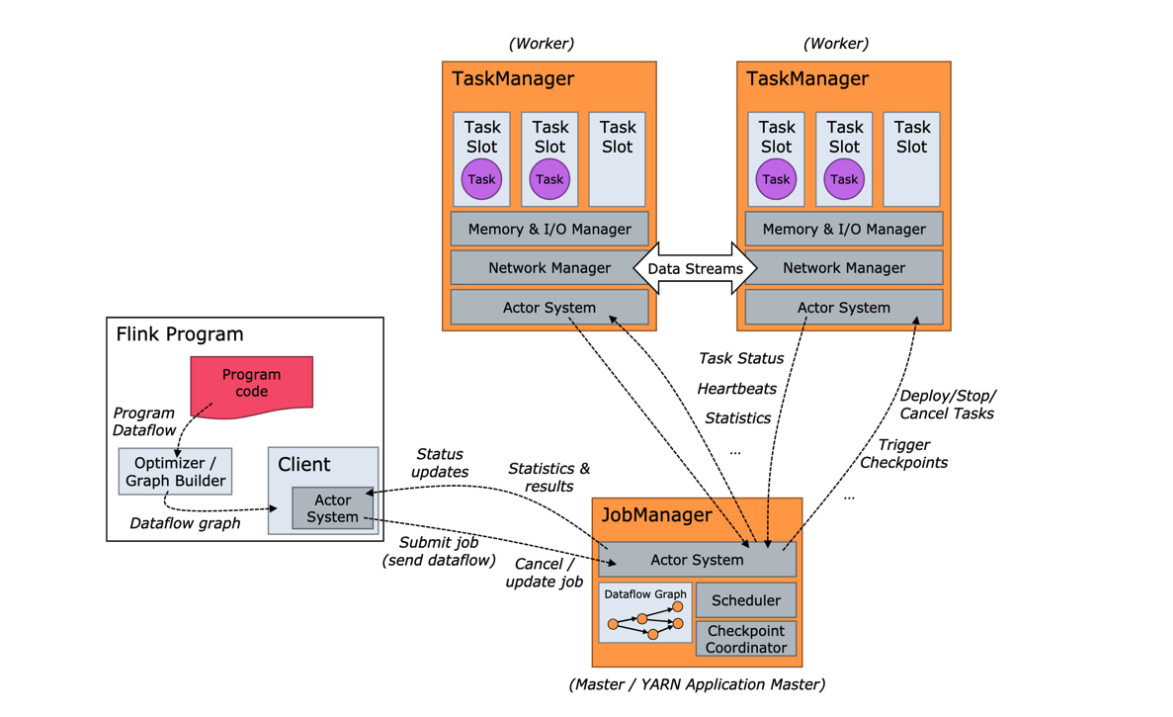
架构概览
- runtime架构:

Job
- 通过DataStream API, DataSet API, SQL和Table API 编写Flink任务, 会生成一个JobGraph (由 source, map, keyBy, window, apply和sink等算子组成)
- 当JobGraph提交给Flink集群后, 能够以Local, Standalone, Yarn和K8s四种模式运行
JobManager
- 概述:
- 控制一个应用程序执行的主进程, 每个应用程序都会被一个不同的JobManager所控制执行
- JobManger会先接收到要执行的应用程序, 这个应用包括: 作业图 (JobGraph), 逻辑数据流图 (logical dataflow graph) 和打包了所有的类库及其他资源jar包.
- JobManager会把JobGraph转换成一个物理层面的数据流图 (ExecutionGraph), 该执行图包含了所有可以并发执行的任务.
- JobManager会向资源管理器 (ResourceManager) 请求执行任务必要的资源, 也就是任务管理器 (TaskManager) 上的插槽 (slot). 一旦它获取到了足够的资源, 就会将执行图分发到真正运行它们的 TaskManager 上. 而在运行过程中, JonManager会负责所有需要中央协调的操作, 如检查点 (checkpoints) 的协调.
- 功能:
- 将JobGraph 转换成Execution Graph, 最终将Execution Graph拿来运行
- Schedule组件负责Task的调度
- Checkpoint Coordinator组件负责协调整个任务的Checkpoint (包括开始和完成)
- 通过Actor System 与Task Manager进行通信
- 其它一些功能, 如Recovery Metadata, 用于进行故障恢复, 可以从Metadaa里面读取数据
TaskManager
- 概述:
- Flink中的工作进程. 通常在Flink中会有多个TaskManager运行, 每一个TaskManager都包含一定数量的插槽 (slots), 插槽的数量限制了TaskManager能够执行的任务数量.
- 启动之后, TaskManager会向资源管理器注册它的插槽, 收到资源管理器的指令后, TaskManager将会将一个或者多个插槽提供给JobManager调用, JobManager就可以向插槽分配任务 (Tasks) 来执行了.
- 在执行过程中, 一个TaskManager可以跟其他运行同一应用程序的TaskManager交换数据.
- 组件:
- Memory & I/O Manager, 即内存I/O的管理
- Network Manager, 用来对网络方面进行管理
- Actor system, 用来负责网络的通信
ResourceManager
- 主要负责管理任务管理器 (TaskManager) 的插槽 (slot), TaskManager插槽是Flink中定义的处理资源单元.
- 提供YARN, Mesos, K8s及standlone部署.
- 当JobManager申请插槽资源时, ResourceManager会将有空闲插槽的TaskManager分配给JobManager. 如果ResourceManager没有足够的插槽来满足JobManager的请求, 它还可以向资源提供平台发起会话, 以提供启动TaskManager进程的容器.
子组件
Dispatcher (分发器)
- 可跨作业运行, 它为应用提交提供了REST接口.
- 当一个应用被提交执行时, 分发器就会启动并将应用移交给一个JobManager.
- Dispatcher也会启动一个Web UI, 用来方便地展示和监控作业执行的信息.
- Dispatcher在架构中可能并不是必须的, 取决于应用程序提交运行的方式.
安装配置
版本选择
- 1.9: 开始支持Hive集成, 并未完全兼容
- 1.10:
- 完成Blink向Flink的合并
- 内存管理优化
- Batch兼容Hive且生产可用
- 对SQL的DDL进行增强
- 支持Python UDF
- 原生k8s初步集成
- SQL Client CLI Beta版本, 仅支持embedded模式
- 1.11:
- 新的JobManager内存模型
- Blink作为默认的planner
standlone
wget https://archive.apache.org/dist/flink/flink-1.10.1/flink-1.10.1-bin-scala_2.11.tgz
tar -zxf flink-1.10.1-bin-scala_2.11.tgz
单机standalone
# 启动
./bin/start-cluster.sh
# 停止
./bin/stop-cluster.sh
- web页面查看:
http://localhost:8081
多机 Standalone 集群
- 配置
- conf/masters: host配置
- conf/slaves: host配置
- conf/flink-conf.yaml
jobmanager.rpc.address: cdh00
- 启动集群
HighAvailability(HA)部署和配置
- JobManager 是整个系统中最可能导致系统不可用的角色, 在生产业务使用 Standalone 模式,则需要部署配置 HA (flink 1.6+)
- 配置
# conf/masters 增加 JobManager的host
# conf/flink-conf.yaml
# 配置high-availability mode
high-availability: zookeeper
# 配置zookeeper quorum(hostname和端口需要依据对应zk的实际配置)
high-availability.zookeeper.quorum: cdh01:2181,cdh02:2181,cdh03:2181
# (可选)设置zookeeper的root目录
high-availability.zookeeper.path.root: /test_dir/test_standalone_root
# (可选)相当于是这个standalone集群中创建的zk node的namespace
high-availability.cluster-id: /test_dir/test_standalone
# JobManager的meta信息放在dfs,在zk上主要会保存一个指向dfs路径的指针
high-availability.storageDir: hdfs:///test_dir/recovery/
Flink on YARN
- 分两种模式:
- Job Mode: 每次提交Flink任务都会创建一个专用的Flink集群, 任务完成后资源释放
- Session Mode: 在YARN中提前初始化一个Flink集群, 以后所有Flink任务都提交到这个集群
- 优点:
- 资源按需使用,提高集群的资源利用率
- 任务有优先级,根据优先级运行作业
- 基于 Yarn 调度系统,能够自动化地处理各个角色的 Failover
- JobManager 进程和 TaskManager 进程都由 Yarn NodeManager 监控
- 如果 JobManager 进程异常退出,则 Yarn ResourceManager 会重新调度 JobManager 到其他机器
- 如果 TaskManager 进程异常退出,JobManager 会收到消息并重新向 Yarn ResourceManager 申请资源,重新启动 TaskManager
在Yarn上启动Long Running的Flink集群 (Session CLuster模式)
# 查看命令参数
./bin/yarn-session.sh -h
# 创建一个 Yarn 模式的 Flink 集群
./bin/yarn-session.sh -n 4 -jm 1024m -tm 4096m
# 默认使用 /tmp/.yarn-properties-${user} 文件中保存的上一次创建 Yarn session 的集群信息
./bin/flink run examples/streaming/WordCount.jar --input hdfs:///test_dir/input_dir/story --output hdfs:///test_dir/output_dir/output
# 指定Yarn上的Application ID
./bin/flink run -yid application_1548056325049_0048 examples/streaming/WordCount.jar --input hdfs:///test_dir/input_dir/story --output hdfs:///test_dir/output_dir/output
- 参数:
-n (--container): TaskManager 的数量-jm (–jobManagerMemory): JobManager 的内存(单位 MB).-tm (–taskManagerMemory): 每个 taskmanager 的内存 (单位 MB).-qu: queue Specify YARN queue-s (--slots): 每个 TaskManager 的 slot 数量, 默认一个 slot 一个 core, 默认每个 taskmanager 的 slot 的个数为 1, 有时候可以多一些 taskmanager, 做冗余.-t (--ship): Ship files in the specified directory (t for transfer)-nm: yarn 的appName yarn ui 上名字).-d: 后台执行.
在Yarn上运行单个 Flink job(Job Cluster模式)
./bin/flink run -m yarn-cluster -yn 2 examples/streaming/WordCount.jar --input hdfs:///test_dir/input_dir/story --output hdfs:///test_dir/output_dir/output
Yarn 模式下的 HA 配置
<!-- Yarn 集群级别 AM 重启的上限 -->
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>100</value>
</property>
yarn.application-attempts: 10 # 1+ 9 retries
# 配置high-availability mode
high-availability: zookeeper
# 配置zookeeper quorum(hostname和端口需要依据对应zk的实际配置)
high-availability.zookeeper.quorum: cdh01:2181,cdh02:2181,cdh03:2181
# (可选)设置zookeeper的root目录
high-availability.zookeeper.path.root: /test_dir/test_standalone2_root
# 删除这个配置
# high-availability.cluster-id: /test_dir/test_standalone2
# JobManager的meta信息放在dfs,在zk上主要会保存一个指向dfs路径的指针
high-availability.storageDir: hdfs:///test_dir/recovery2/
编译安装CDH版本
下载制作包
# 下载制作包
git clone https://github.com/pkeropen/flink-parcel.git
修改配置文件
#FLINK 下载地址
FLINK_URL=https://archive.apache.org/dist/flink/flink-1.10.1/flink-1.10.1-bin-scala_2.11.tgz
#flink版本号
FLINK_VERSION=1.10.1
#扩展版本号
EXTENS_VERSION=BIN-SCALA_2.11
#操作系统版本,以centos为例
OS_VERSION=7
#CDH 小版本
CDH_MIN_FULL=5.2
CDH_MAX_FULL=5.15
#CDH大版本
CDH_MIN=5
CDH_MAX=5
生成parcel文件
生成csd文件
CDH 中安装flink服务
- 配置flink parcel和csd文件
- 激活flink
- 添加flink服务
Flink State 与 CheckPoint
state
keyed state
operator state (non-keyed state)
- 每一个operator state都仅与一个operator的实例绑定
checkpoint
- state就是checkpoint所做的主要持久化备份的主要数据
- 常见的source state, 例如记录当前source的offset
执行机制
- Checkpoint Coordinator向所有source节点trigger Check-point
- source 节点向下游广播barrier (实现Chandy-Lamp-ort分布式快照算法核心), 下游task只有接收到所有input的barrier才会执行相应的Checkpoint
- 当task完成state备份后, 会将备份数据的地址 (state handle) 通知给 Checkpoint coordinator
- 下游sink节点收集齐上游input barrier之后, 会执行本地快照, 同样sink节点完成自身的checkpoint之后, 会将 state haddle返回通知Coordinator
- 最后当Checkpoint Coordinator收集齐所有task的state handle, 就认为这一次的checkpoint全局完成了, 向持久化存储中再备份一个Checkpoint meta文件
程序与数据流
- 所有的Flink程序都是由三部分组成: source, Transformation 和 Sink
流处理API
- map/flatMap/filter
- keyBy
- 聚合操作:
- 滚动聚合算子 (Rolling Aggregation)
- reduce:
- 合并当前的元素和上次聚合的结构, 产生一个新的值,返回的流中包含每一次聚合的结果,而不是 只返回最后一次聚合的最终结果。
- split 和 select
- connect 和 coMap/coFlatMap
- Union
UDF
- MapFunction, FilterFunction, ProcessFunction等
- Lambda Functions
- Rich Functions
Source
- 定义数据源
- 预定义:
- 文件:
readTextFile, readFile - 集合:
fromElements, fromCollection, fromParallelCollection, generateSequence - Socket:
socketTextStream
- connectors: RabbitMQ/kafka, Apache Bahir
- 自定义source:
Sink
- 对外的输出通过sink来完成
- 预定义:
- 文件:
writeAsText(), writeAsCsv(), writeUsingOutputFormat, FileOutputFormat - socket:
writeToSocket - console:
print, printToErr
- connectors: hdfs/RabbitMQ/kafka/redis/es/nifi, Apache Bahir
- 自定义sink:
窗口
- 分类:
- CountWindow: 按照指定的数据条数生成一个 Window,与时间无关。
- TimeWindow: 按照时间生成 Window。
- 窗口分配器: window()方法, 必须在keyBy之后才能使用.
TimeWindow
滚动窗口(Tumbling Windows)
- 概述: 将数据依据固定的窗口长度对数据进行切片.Flink的默认时间窗口, 根据Processing Time进行窗口划分.
- 特点: 时间对齐, 窗口长度固定, 没有重叠.
- 适用场景: 适合做 BI 统计等(做每个时间段的聚合计算).
- API
滑动窗口(Sliding Windows)
- 概述: 滑动窗口是固定窗口的更广义的一种形式, 滑动窗口由固定的窗口长度和滑动间隔组成.
- 特点: 窗口长度固定, 可以有重叠.
- 适用场景:对最近一个时间段内的统计 (求某接口最近 5min 的失败率来决定是否要报警).
- API
- timeWindow(window_size, sliding_size)
会话窗口(Session Windows)
- 概述: 由一系列事件组合一个指定时间长度的 timeout 间隙组成, 类似于 web 应用的session, 也就是一段时间没有接收到新数据就会生成新的窗口.
- 特征: 时间无对齐
CountWindow
- 按照指定的数据条数生成一个 Window, 与时间无关.
滚动窗口
- 概述: 默认的 CountWindow 是一个滚动窗口,只需要指定窗口大小即可,当元素数量达到窗口大小时,就会触发窗口的执行。
- API
滑动窗口
- API
- countWindow(window_size, sliding_size)
window function
类别
- 增量聚合函数(incremental aggregation functions)
- 每条数据到来就进行计算,保持一个简单的状态。
- 典型的增量聚合函数有 ReduceFunction, AggregateFunction。
- 全窗口函数(full window functions)
- 先把窗口所有数据收集起来,等到计算的时候会遍历所有数据。
- ProcessWindowFunction 就是一个全窗口函数。
其他
- trigger() —— 触发器
- 定义 window 什么时候关闭,触发计算并输出结果
- evitor() —— 移除器
- allowedLateness() —— 允许处理迟到的数据
- sideOutputLateData() —— 将迟到的数据放入侧输出流
- getSideOutput() —— 获取侧输出流
时间语义与Watermark
时间语义
- Event Time: 是事件创建的时间.它通常由事件中的时间戳描述, 例如采集的日志数据中, 每一条日志都会记录自己的生成时间, Flink 通过时间戳分配器访问事件时间戳.
- Ingestion Time: 是数据进入 Flink 的时间.
- Processing Time: 是每一个执行基于时间操作的算子的本地系统时间, 与机器相关, 默认的时间属性就是 Processing Time.
Watermark
- 作用:
- 用于处理乱序事件的,而正确的处理乱序事件,通常用 Watermark 机制结合 window 来实现。
- 遇到一个时间戳达到了窗口关闭时间,不应该立刻触发窗口计算,而是等待一段时间,等迟到的数据来了再关闭窗口
Timestamp 分配和 Watermark生成
- 方式:
- 在SourceFunction中, 通过collectWithTimestamp方法发送一条数据或者emitWatermark去产生一条watermark (表示接下来不会再有时间戳小于等于这个数值记录)
- 调用DataStream.assiginTimestampAndWatermarks
Watermark 传播
- 策略
- watermark会以广播的形式在算子之间传播
- 若接受到Long.MAX_VALUE这个数值的watermark, 相当于是终止标志
- 对于有多个输入的算子watermark原则是: 单输入取其大, 多输入取小 (类似木桶效应)
- 特点:
- 幂等
- 不足:
- 时钟不同步将会带来性能开销, TimeService设置过期
Table API 与 SQL
- Flink 对批处理和流处理,提供了统一的上层 API
- Table API 是一套内嵌在 Java 和 Scala 语言中的查询API,它允许以非常直观 的方式组合来自一些关系运算符的查询
- Flink 的 SQL 支持基于实现了 SQL 标准的 Apache Calcite (SQL 解析工具)
DataStream 与 Table 互转
// DataStream 转为 Table
tableEnv.fromDataStream(dataStream)
// Table 转为 DataStream (需要指定类型) 追加模式
tableEnv.toAppendStream[Row](resultTable)
// Table 转为 DataStream (需要指定类型) 撤回模式: 聚合操作后的方式
tableEnv .toRetractStream[(String, Long)](aggResultTable)
SQL client
# 启动, 暂不支持远程连接
./bin/sql-client.sh embedded
Flink CEP
- 简介:
- CEP 的意思是复杂事件处理,例如:起床–>洗漱–>吃饭–>上班等一系列串联起来的事件流形成的模式称为 CEP。如果发现某一次起床后没有刷牙洗脸亦或是吃饭就直接上班,就可以把这种非正常的事件流匹配出来进行分析,看看今天是不是起晚了.
- 应用场景
- 风险控制: 对用户异常行为模式进行实时检测,当一个用户发生了不该发生的行为,判定这个用户是不是有违规操作的嫌疑。
- 策略营销: 用预先定义好的规则对用户的行为轨迹进行实时跟踪,对行为轨迹匹配预定义规则的用户实时发送相应策略的推广。
- 运维监控: 灵活配置多指标、多依赖来实现更复杂的监控模式。
原理
- Flink CEP 内部是用 NFA(非确定有限自动机)来实现的,由点和边组成的一个状态图,以一个初始状态作为起点,经过一系列的中间状态,达到终态。
- 点分为起始状态、中间状态、最终状态三种.
- 边分为 take、ignore、proceed 三种.
- take:必须存在一个条件判断,当到来的消息满足 take 边条件判断时,把这个消息放入结果集,将状态转移到下一状态。
- ignore:当消息到来时,可以忽略这个消息,将状态自旋在当前不变,是一个自己到自己的状态转移。
- proceed:又叫做状态的空转移,当前状态可以不依赖于消息到来而直接转移到下一状态.
组件
- Event Stream
- pattern 定义
- pattern 检测
参考