多元统计之因子分析
概述
- 研究观测变量变动的共同原因和特殊原因, 从而达到简化变量结构目的的多元统计方法
应用
- 寻求变量的基本结构, 简化变量系统
- 用于分类, 根据因子得分值, 在因子轴所构成的空间中将变量或者样本进行分类(能够分析样品间差异的原因)
类型
- R型因子分析
- Q型因子分析
因子分析模型
因子分析的数学模型
R型因子分析模型
概述:
- R型因子分析是将每一个变量都表示成公共因子的线性函数与特殊因子之和, 即 $$X_i = a_{i1}F_1 + a_{i2}F_2 + \cdots + a_{im}F_m + \epsilon_i, \quad (i=1,2,\cdots, p) \tag{2.1.1-1}$$
上式中的 $F_1,F_2,\cdots,F_m$ 称为公共因子, $\epsilon_i$ 称为 $X_i$ 的特殊因子。该模型可用矩阵表示为:
$$X = AF + \epsilon$$ $$\begin{bmatrix} X_1 \ X_2 \ \vdots \ X_p \end{bmatrix} = \begin{bmatrix} \epsilon_1 \ \epsilon_2 \ \vdots \ \epsilon_p \end{bmatrix} + A_{p \times m}\begin{bmatrix} F_1 \ F_2 \ \vdots \ F_m \end{bmatrix} \tag{2.1.1-2} $$
构造模型满足:
- $m \le p$
- $Cov(F, \epsilon) = 0$, 即公共因子与特殊因子是不相关的
- $D_F = D(F) = I_m$, 即各个公共因子不相关且方差为1
- 各个特殊因子不相关, 方差不要求相等
$$D_{\epsilon} = D(\epsilon) = \begin{bmatrix} \sigma_1^2 & & & 0 \ & \sigma_2^2 & & \ & & \ddots & \ 0 & & & \sigma_p^2 \end{bmatrix}$$
公共因子(潜在因子)是不可观测变量且只存在于某种理论意义之中, 可理解为在高维空间中的互相垂直的m个坐标轴。虽然潜在变量不能直接测得, 但它一定与某些可测变量有着某种程度的关联。
Q型因子分析(因子得分)
- 概述:
- 类似地, Q型因子分析数学模型可表示为: $$X_i = a_{i1}F_1 + a_{i2}F_2 + \cdots + a_{im}F_m + \epsilon_i, \quad (i=1,2,\cdots, n) \tag{2.1.1-3}$$
- Q型因子分析与R型因子分析模型的差体现在$X_1, X_2, \cdots, X_n$表示的是n个样品。
- 主成分分析与因子分析的异同
- 相同点:
- R型或Q型因子分析都用公因子F代替X, 一般要求$m<p, m<n$, 因此因子分析与主成分分析一样, 也是一种降低变量维度数的方法。
- 因子分析求解过程同主成分分析类似, 也是从一个协方差阵出发的。
- 区别:
- 主成分分析的数学模型本质上是一种线性变化, 将原始坐标变换到变异程度大的方向, 突出数据变异的方向, 归纳重要信息。
- 因子分析从本质上看是从显在变量去"提炼"潜在因子的过程。并且因子的形式也不是唯一确定的。一般来说, 作为"自变量"的因子$F_1,F_2,\cdots,F_m$是不可直接观测的。
- 相同点:
因子载荷阵
因子载荷阵不唯一的原因
- 变量X的协差阵$\Sigma$的分解式为
$$ \begin{aligned} D(X) & = D(AF + \epsilon) = E[(AF + \epsilon)(AF + \epsilon)’] \ & = AE(FF’)A’ + AE(F\epsilon’) + E(\epsilon F’)A’ + E(\epsilon\epsilon’) \ & = AD(F)A’ + D(\epsilon) \ & = AA’ + D(\epsilon) \end{aligned} $$
如果X为标准化的随机向量, 则$\Sigma$就是相关矩阵$R = (\rho_{ij}), 即R = AA’ + D_{\epsilon}$
对于$m \times m$的正交矩阵T, 令$A^* = AT, F^* = T’F$, 模型可表示为: $
$X = A^*F^* + \epsilon$$
由于$$Cov(F^, \epsilon) = E(F^\epsilon’) = T’E(F\epsilon’) = 0 \ D(F^*) = T’D(F)T = T’T = I_{m \times m}$$
所以仍满足模型的条件
同样$\Sigma$也可以分解为$$\Sigma = A^*A^{*'} + D_{\epsilon}$$
因子载荷阵的统计意义
因子载荷$a_{ij}$的统计意义
- 对于因子模型
$$X_i = a_{i1}F_1 + a_{i2}F_2 + \cdots + a_{ij}F_j + \cdots + a_{im}F_m + \epsilon_i \quad (i=1,2,\cdots,p)$$
- 可得$X_i与F_j$的协方差为:
$$\begin{aligned} Cov(X_i,F_j) & = Cov(\sum_{k=1}^ma_{ik}F_k + \epsilon, F_j) \ & = Cov(\sum_{k=1}^ma_{ik}F_k, F_j) + Cov(\epsilon_i, F_j) \ & = a_{ij} \end{aligned}$$
- 若对$X_i$做了标准化处理, $X_i$的标准差为1, 且$F_j$的标准差为1, 有 $$ r_{X_i,F_j} = \frac{Cov(X_i,F_j)}{\sqrt{D(X_i)}\sqrt{D(F_j)}} = Cov(X_i,F_j) = a_{ij} $$
- 那么, 对于标准化后的$X_i$, $a_{ij}$是$X_i$与$F_j$的相关系数, 表示$X_i$依赖$F_j$的分量(比重)。因此统计学上也称其为权。
- 历史原因, 心理学家将它叫做载荷, 表示第i个变量在第j个公共因子上的载荷, 反应了第i个变量在第j个公共因子上的相对重要性。
变量共同度的统计意义
- 由因子模型, 知
$$\begin{aligned} D(X_i) & = a_{i1}^2D(F_1) + a_{i2}^2D(F_2) + \cdots + a_{im}^2D(F_m) + D(\epsilon_i) \ & = a_{i1}^2 + a_{i2}^2 + \cdots + a_{im}^2 + D(\epsilon_i) \ & = h_i^2 + \sigma_i^2 \end{aligned}$$
- 变量$X_i$的共同度为: $h_i^2 = \sum_{j=1}^ma_{ij}^2 \quad i=1,2,\cdots,p$
- 如果对$X_i$作了标准化处理, 有 $$1 = h_i^2 + \sigma_i^2$$
公因子$F_i$的方差贡献率$g_j^2$的统计意义
- 设因子载荷矩阵为$A$, 称第j列元素的平方和, 即: $$g_j^2 = \sum_{i=1}^pa_{ij}^2 \quad j=1,2,\cdots,m$$ 为公共因子$F_j$对X的贡献, 即$g_j^2$表示同一个公共因子$F_j$对各变量所提供的方差贡献之总和, 反映该因子对全部变量的总影响
- 它是衡量每一个公共因子相对重要性的一个尺度。公共因子$F_j$的相对重要性可用$g_j^2/h$来衡量, 它称为公共因子$F_j$对X的贡献率。
- 因子分析的目的就是要由原始随机向量的协差阵$\Sigma$或相关阵$R$求出因子分析模型的解, 即求出载荷阵$A$和特性方差阵$D_\epsilon$, 并给公因子赋予有实际背景的解释。
因子载荷矩阵求解
主成分法
- 概述:
- 在进行因子分析之前先对数据进行一次主成分分析, 然后把前几个主成分作为未旋转的公共因子。
- 该方法所得的特殊因子$\epsilon_1,\epsilon_2,\cdots,\epsilon_p$之间并不相互独立, 不完全符合因子模型的假设前提。
- 当共同度较大时, 特殊因子所起的作用较小, 特殊因子之间的相关性所带来的影响几乎可以忽略。
求解方法
假定从相关阵出发求解主成分, 设有p个变量, 则可以找出p个主成分$Y_1,Y_2,\cdots,Y_p$(按由大到小顺序排列), 则主成分与原始变量之间存在如下关系式:
$$ \begin{cases} Y_1 = \gamma_{11}X_1 + \gamma_{12}X_2 + \cdots + \gamma_{1p}X_p \ Y_2 = \gamma_{21}X_1 + \gamma_{22}X_2 + \cdots + \gamma_{2p}X_p \ \cdots\cdots \ Y_p = \gamma_{p1}X_1 + \gamma_{p2}X_2 + \cdots + \gamma_{pp}X_p \ \end{cases} \tag{3.1.1-1} $$
式中, $\gamma_ij$为随机变量X的相关矩阵的特征根所对应的特征向量的分量, 因为特征向量之间彼此正交, 从X到Y的转换关系式可逆的, 则可得出由Y到X的转换关系为:
$$ \begin{cases} X_1 = \gamma_{11}Y_1 + \gamma_{21}Y_2 + \cdots + \gamma_{p1}Y_p \ X_2 = \gamma_{12}Y_1 + \gamma_{22}Y_2 + \cdots + \gamma_{p2}Y_p \ \cdots\cdots \ X_p = \gamma_{1p}Y_1 + \gamma_{2p}Y_2 + \cdots + \gamma_{pp}Y_p \ \end{cases} \tag{3.1.1-2} $$
对上面每一等式只保留前m个主成分而把后面的部分用$\epsilon_i$代替, 则式(3.1.1-2)转化为:
$$ \begin{cases} X_1 = \gamma_{11}Y_1 + \gamma_{21}Y_2 + \cdots + \gamma_{m1}Y_m + \epsilon_1 \ X_2 = \gamma_{12}Y_1 + \gamma_{22}Y_2 + \cdots + \gamma_{m2}Y_m + \epsilon_2 \ \cdots\cdots \ X_p = \gamma_{1p}Y_1 + \gamma_{2p}Y_2 + \cdots + \gamma_{mp}Y_m + \epsilon_p \ \end{cases} \tag{3.1.1-3} $$
该式与因子模型(2.1.1-2)相一致, 并且$Y_i=(i=1,2,\cdots,m)$之间相互独立。将$Y_i$转化成合适的公共因子, 只需将主成分$Y_i$变成方差为1的变量, 即除以其标准差(特征根的平方根), 则可令$F_i = Y_i/\sqrt{\lambda_i}, \quad a_{ij} = \gamma_{ji}$, 式(3.1.1-3)变为:
$$ \begin{cases} X_1 = a_{11}F_1 + a_{12}F_2 + \cdots + a_{1m}F_m + \epsilon_1 \ X_2 = a_{21}F_1 + a_{22}F_2 + \cdots + a_{2m}F_m + \epsilon_2 \ \cdots\cdots \ X_p = a_{p1}F_1 + a_{p2}F_2 + \cdots + a_{pm}F_m + \epsilon_p \end{cases} \tag{3.1.1-4} $$
这与因子模型完全一致, 这样就得到了载荷矩阵$A$和一组初始公共因子(未旋转)。
一般设$\lambda_1,\lambda_2,\cdots,\lambda_p \quad (\lambda_1 \ge \lambda_2 \ge \cdots \ge \lambda_p)$为样本相关矩阵R的特征根, $\gamma_1,\gamma_2,\cdots,\gamma_p$为对应的标准化正交化特征向量。设$m < p$, 则因子载荷矩阵A的一个解为:
$$\widehat{A} = (\sqrt{\lambda_1}\gamma_1, \sqrt{\lambda_2}\gamma_2,\cdots,\sqrt{\lambda_m}\gamma_m) \tag{3.1.1-5}$$ 共同度的估计为: $$\widehat{h}i^2 = \widehat{a}{i1}^2 + \widehat{a}{i2}^2 + \cdots + \widehat{a}{im}^2 \tag{3.1.1-6}$$
公因子的数目m, 当用主成分进行因子分析时, 可以借鉴确定主成分个数的准则。一般具体问题具体分析, 总之要使所选取的公共因子能够合理地描述原始变量相关阵的结构, 同时要有利于因子模型的解释。
主轴因子法
- 概述:
- 求解思路与主成分发类似, 均从分析矩阵的结构入手, 不同的地方在于, 主成分发是在所有的p个主成分能解释标准化原始变量所有方差的基础上进行分析的, 而主轴因子法中, 假定m个公共因子只能解释原始变量的部分方差, 利用公共因子方差(或共同度)来代替相关矩阵主对角线上的元素1, 并以新得到的这个矩阵(称为调整相关矩阵)为出发点, 对其分别求解特征根与特征向量并得到因子解。
求解方法
在因子模型(2.1.1-1)中, 不难得到如下关于X的相关矩阵R的关系式: $$R = AA’ + \Sigma_\epsilon$$ 式中A为因子载荷矩阵, $\Sigma_\epsilon$为一对角阵, 其对角元素为相应特殊因子的方差。则称$
$R^* = R -\Sigma_\epsilon = AA'$$为调整相关矩阵, 显然$$R^*$$的主对角元素不再是1, 而是共同度$h_i^2$。分别求解$R^*$的特征值与标准正交特征向量, 进而求出因子载荷矩阵A。此时, $$R^*$$有m个正的特征值。设$$\lambda_1^* \ge \lambda_2^* \ge \cdots \ge \lambda_m^*$$为$$R^*$$的特征根, $$\gamma_1^*, \gamma_2^*, \cdots, \gamma_m^*$$为对应的标准正交话特征向量。m < p, 则因子载荷矩阵A的一个主轴因子解为:$$\widehat{A} = (\sqrt{\lambda_1^}\gamma_1^, \sqrt{\lambda_2^}\gamma_2^,\cdots,\sqrt{\lambda_m^}\gamma_m^) \tag{3.1.1.7}$$
注意到, 上面的分析是以首先得到调整相关矩阵$R^$为基础的, 而实际上, $R^$与共同度(或相对的剩余方差)都是未知的, 需要先进行估计。一般先给出一个初始估计, 然后估计出载荷矩阵A后再给出较好的共同度或剩余方差的估计。初始估计的方法有很多, 可尝试对原始变量先进行一次主成分分析, 给出初始估计值。
极大似然法
如果假定公共因子F和特殊因子$\epsilon$服从正态分布, 则能够得到因子载荷和特殊因子方差的极大似然估计。设$X_1,X_2,\cdots,X_p$为来自正态总体$N(\mu,\Sigma)$的随机样本, 其中$\Sigma = AA’ + \Sigma_\epsilon$。从似然函数的理论知
$$ L(\mu, \Sigma) = \frac{1}{(2\pi)^{np/2}|\Sigma|^{n/2}}e^{-1/2tr{\Sigma^{-1}[\sum_{j=1}^n(X_j - \bar{X})(X_j - \bar{X})’ + n(\bar{X} - \mu)(\bar{X} - \mu)’]}} \tag{3.3.1-1} $$
它通过$\Sigma$依赖于A和$\Sigma_\epsilon$, 但式(3.3.1)不能唯一确定A, 为此, 添加如下条件:
$$ A’\Sigma_\epsilon^{-1}A = \Lambda \tag{3.3.1-2} $$
其中$\Lambda$是一个对角阵, 用数值极大化的方法可以得到极大似然估计$\widehat{A}$和$\widehat{\Sigma_\epsilon}$。极大似然估计$\widehat{A}, \widehat{\Sigma_\epsilon}和\widehat{\mu} = \bar{X}$, 将使$\widehat{A}’\widehat{\Sigma}_\epsilon^{-1}\widehat{A}$为对角阵, 使公式(3.3.1-2)达到最大。
公因子重要性的分析
因子旋转
- 概述
- 不管用何种方法确定初始因子载荷矩阵A, 它们都不是唯一的。
- 因所得的初始因子解,各主因子的典型代表变量不是很突出,容易使因子的意义含糊不清,不便于对实际问题进行分析,出于这种考虑,可以对初始公共因进行线性组合,即进行因子旋转。
- 分类:
- 正交旋转: 由初始载荷矩阵A右乘一正交阵得到, 经过正交旋转得到的新公共因子仍然保持彼此独立的性质
- 斜交旋转: 放弃了因子之间彼此独立的限制, 形式更简洁, 其实际意义更容易理解。
- 说明:
- 对于一个具体问题做因子旋转,有时需要多次才能得到满意效果。每一次旋转后,矩阵各列平方的相对方差之和总会比上一次有所增加。如此继续下去,当总方差的改变不大时,就可以停止旋转,这样就得到新的一组公共因子及相应的因子载荷矩阵,使得其各列元素的相对方差之和最大。
因子得分概述
- 因子得分就是公共因子$F_1,F_2,\cdots,F_m$在每一个样品点上的得分。
计算公式
- 因子模型中,公共因子的个数少于原始变量的个数,且是不可观测的隐变量,载荷矩阵A不可逆, 因而不能直接求得公共因子用原始变量表示的精确线性组合。可采用回归的思想求出线性组合系数的估计值,即建立如下以公共因子为因变量,原始变量为自变量的回归方程: $$F_j = \beta_{j1}X_1 + \beta_{j2}X_2 + \cdots + \beta_{jp}X_p, \quad j=1,2,\cdots,m \tag{4.2.1-1}$$ 此处因为原始变量与公共因子变量均为标准化变量, 所以回归模型中不存在常数项。在最小二乘意义下, 可以得到F的估计值: $$\widehat{F} = A’R^{-1}X \tag{4.2.1-2}$$ 式中, A为因子载荷矩阵, R为原始变量的相关阵, X为原始变量向量。
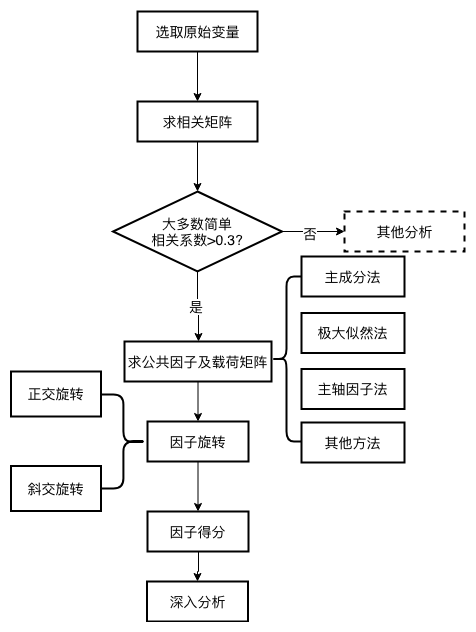
因子分析步骤与逻辑框图
步骤
- 根据研究问题选取原始变量
- 对原始变量进行标准化并求其相关阵, 分析变量之间的相关性
- 求解初始公共因子及因子载荷矩阵
- 因子旋转
- 计算因子得分
- 根据因子得分值进行进一步分析
逻辑框图