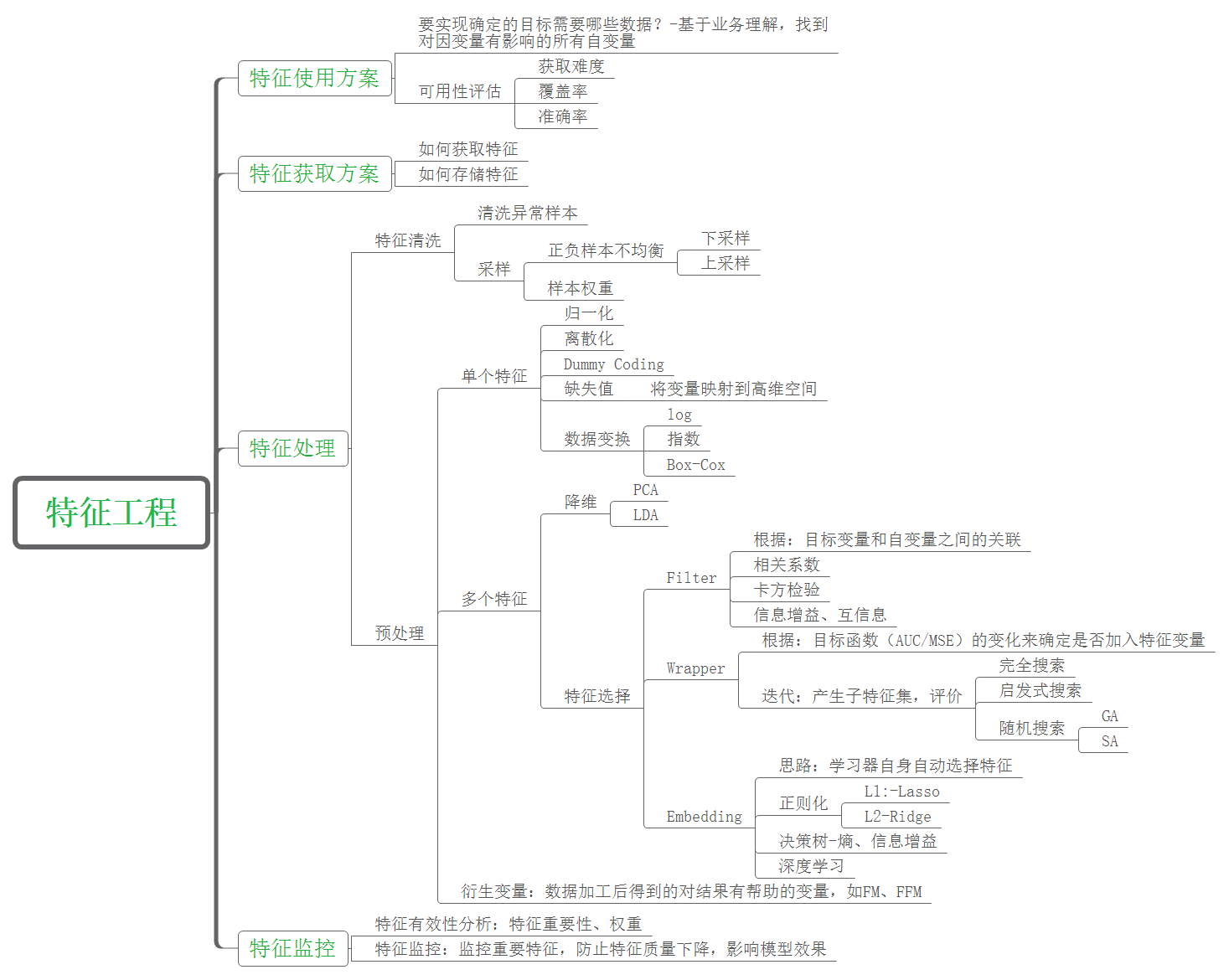
力扣-准时到达的列车最小时速
描述
给你一个浮点数 hour ,表示你到达办公室可用的总通勤时间。要到达办公室,你必须按给定次序乘坐 n 趟列车。另给你一个长度为 n 的整数数组 dist ,其中 dist[i] 表示第 i 趟列车的行驶距离(单位是千米)。每趟列车均只能在整点发车,所以你可能需要在两趟列车之间等待一段时间。例如,第 1 趟列车需要 1.5 小时,那你必须再等待 0.5 小时,搭乘在第 2 小时发车的第 2 趟列车。
返回能满足你准时到达办公室所要求全部列车的 最小正整数 时速(单位:千米每小时),如果无法准时到达,则返回 -1 。
生成的测试用例保证答案不超过 10^7 ,且 hour 的小数点后最多存在两位数字 。